TrialTwin :: Data Flow Analysis
Backstory
In early 2020 our team was engaged by a very large pharma company to conduct an in-depth analysis of how their clinical trial data flows internally.
As a small company, we were surprised they'd choose us instead of the traditional large consulting companies.
Our champion said he wanted to have "a fresh set of eyes" looking at their current challenges. In his words: "a point of view free from pre-existing vendor allegiances."
Our Process
We conducted over a dozen personal interviews (via Zoom) with individuals responsible for every facet of the data flow.
One of our strengths as a consulting company is that we're not pharma experts.
We are database and software experts. This allows us to bring to the table both process as well as implementation suggestions that our clients may not even be aware of.
- What this means is that during our interviews:
first, we questioned the answers ("why do you do things this way?")
then we questioned the questions ("why do you even do this?")
and finally we asked new questions ("if you could eliminate this step in the process, what would be the business value?")
Results
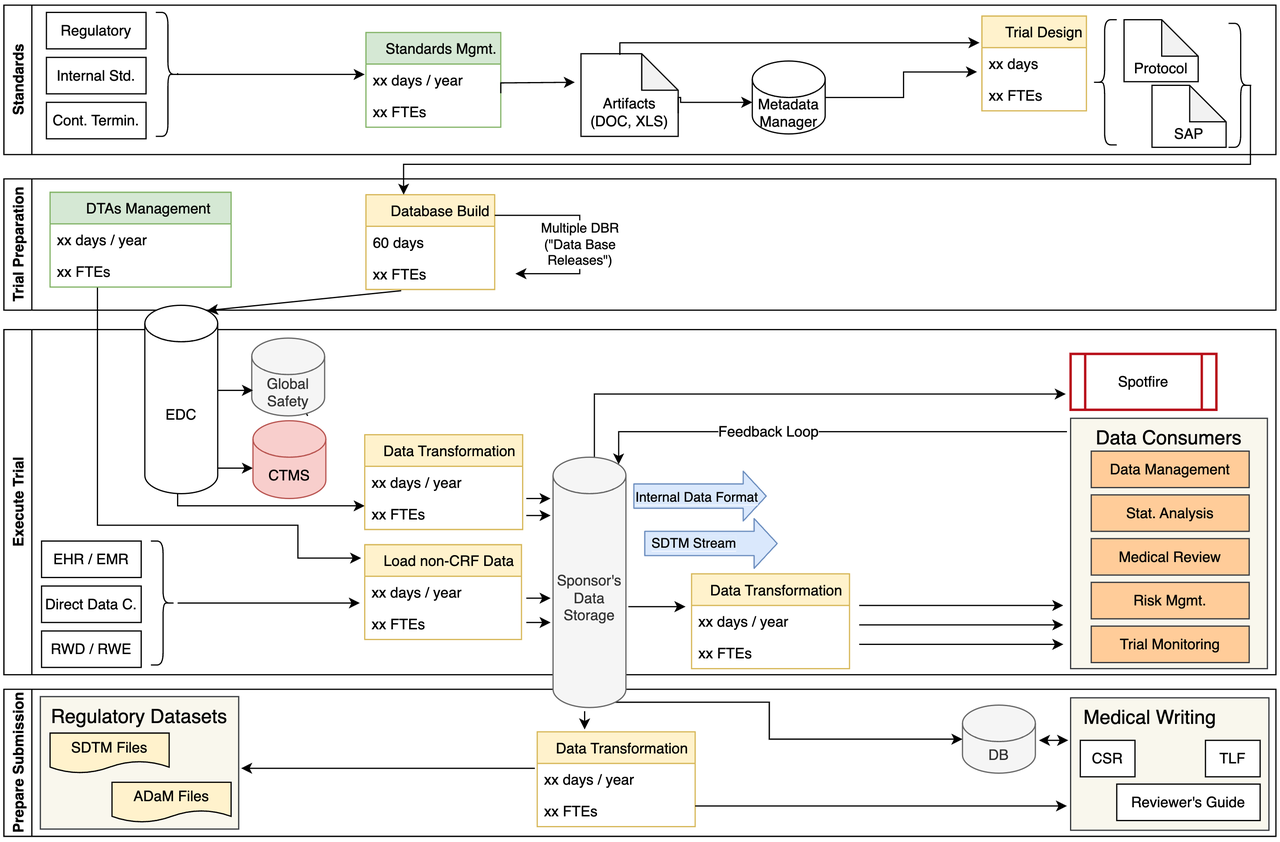
Our study identified many chokepoints, areas of potential data inconsistencies, as well as huge labor costs caused by many manual processes.
The current process, described in detail below, includes many manual processes and multiple data transformations that add significant delays to the submission process.
Standards Management
- Some of the challenges we identified include:
Standards stored in Excel, Word
Difficult to track changes, versions
Long, slow trial design process
Metadata changes are not fully reflected in subsequent processes

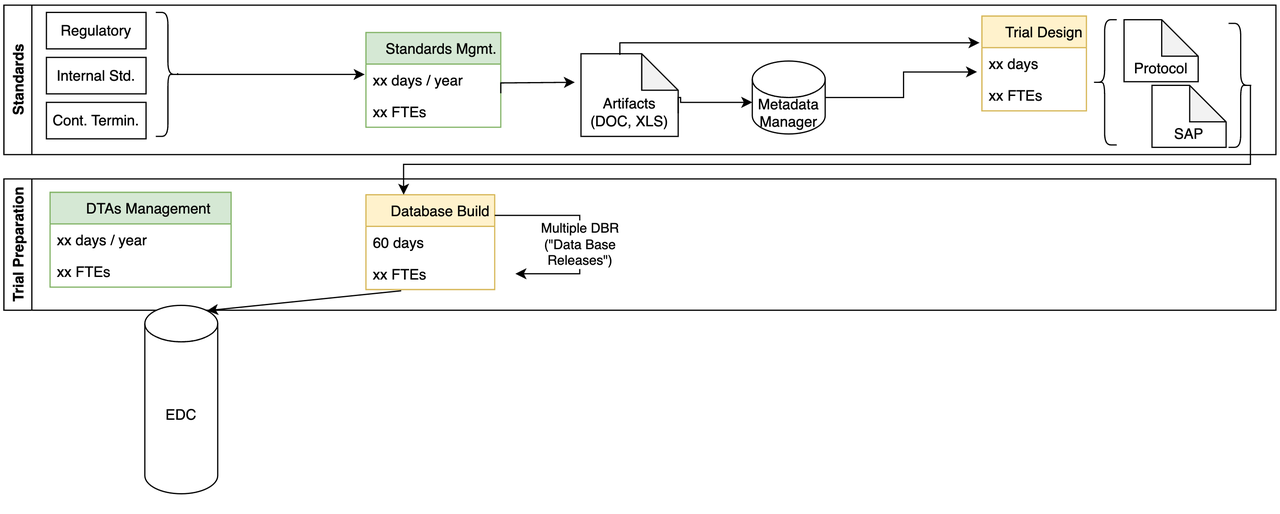
Study Build
- Some of the challenges we identified include:
Takes up to 60 days to build study
Expensive to make form changes
Weak Protocol – build connection
Process tied to specific EDC
Manual integration of external data
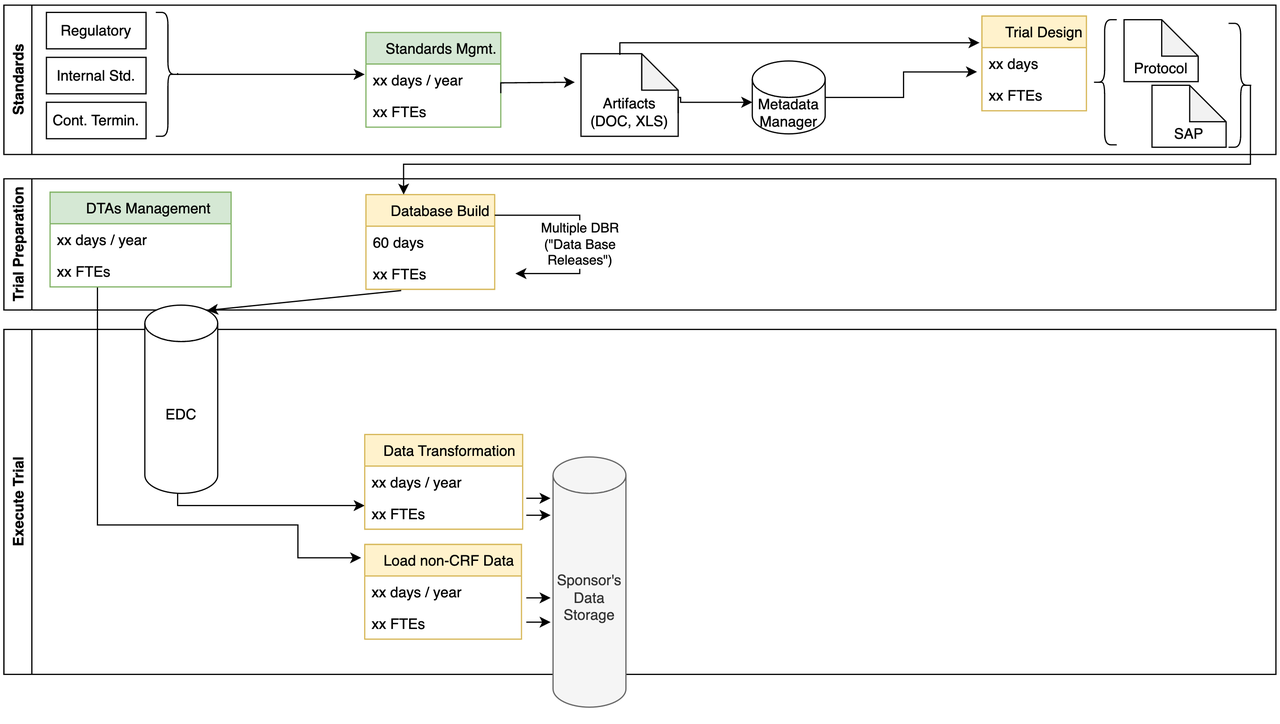
Data Ingestion
- Some of the challenges we identified include:
- Multiple transformations:
extract data from EDC
integrate non-CRF data (labs)
Transformations use old SAS code
Scalability, robustness of storage
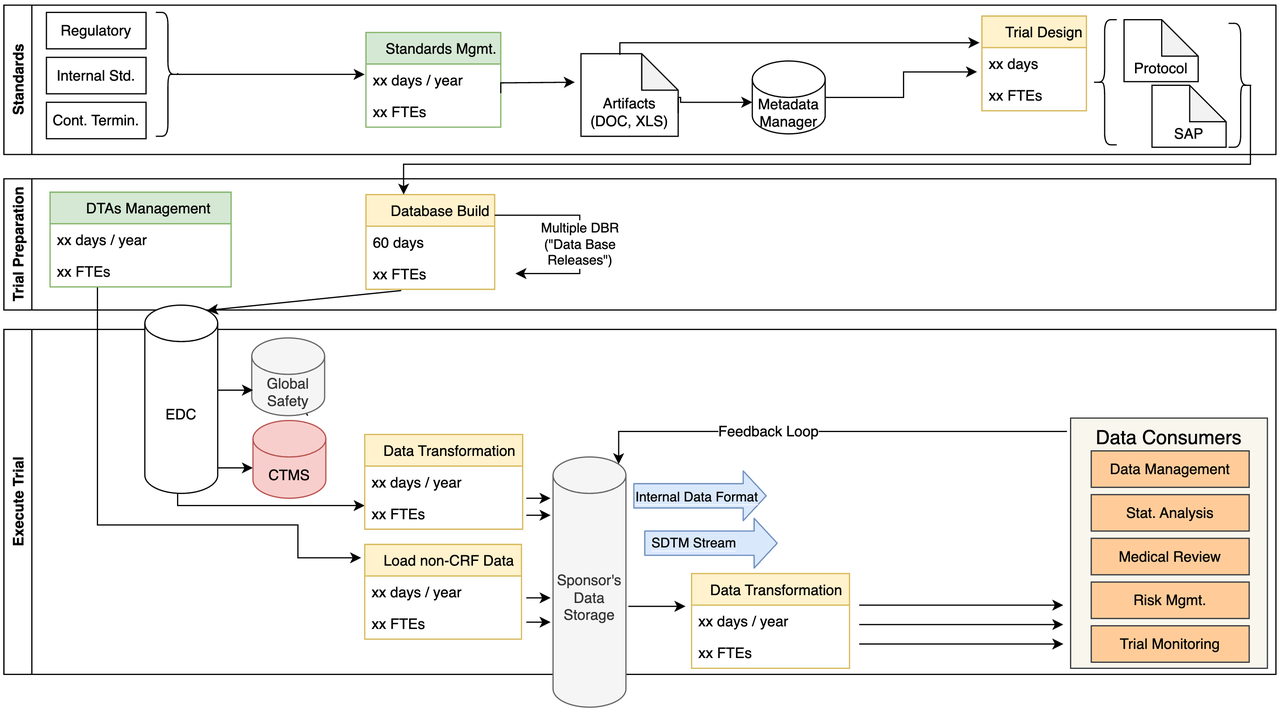
Internal Data Consumers
- Some of the challenges we identified include:
- More transformations:
for each Data Consumer
in multiple formats
Transformations use old SAS code
No feedback loop to metadata
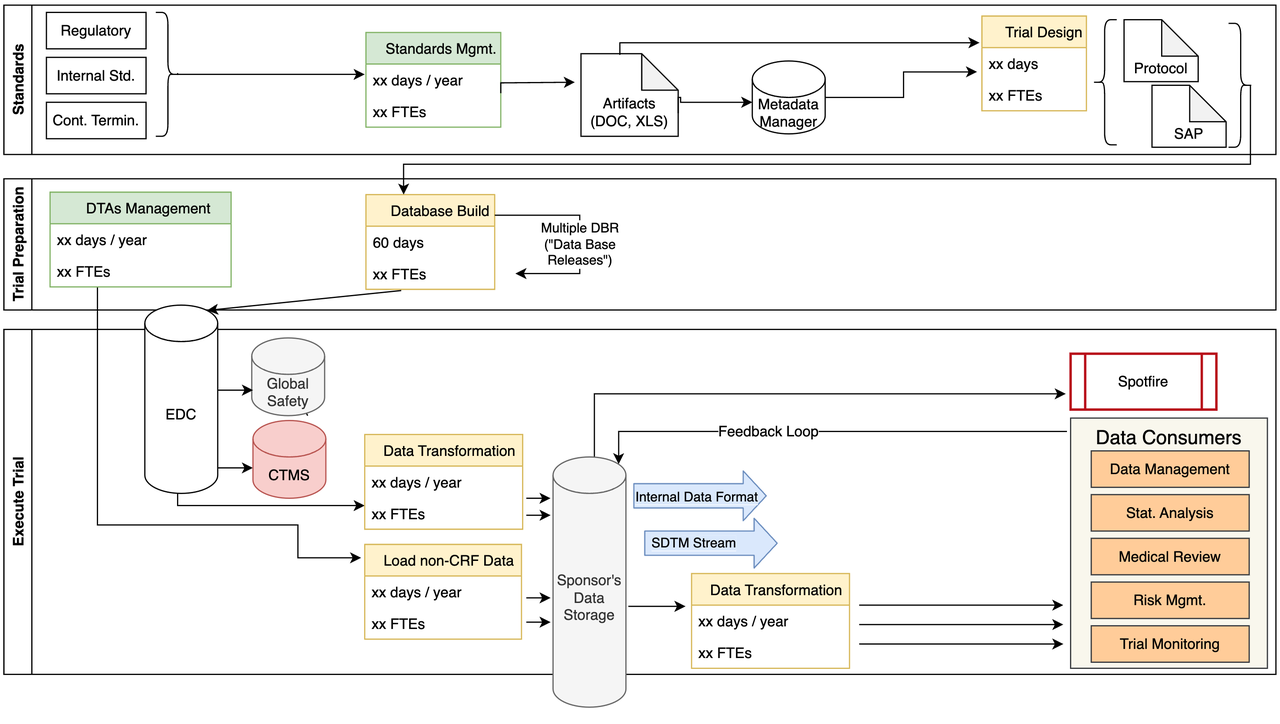
Customized Dashboards
- Some of the challenges we identified include:
Manual creation of study-specific dashboards (Spotfire, Power BI)
No Protocol – dashboard link
Data Conversion for Submission
- Some of the challenges we identified include:
Many transformation SAS macros
Data issues identified very late
Significant labor costs
Potential for human errors
TrialTwin
It's based on this work that we started building our TrialTwin platform.
We do not want to provide just another "patch" on top of obsolete, paper-centric processes. Our vision is a metadata-driven, integrated system that replaces most current spreadsheet-based processes.
TrialTwin combines a metadata-driven repository of both content and data plus automated processing and generation of Synthetic Health Data.
- The TrialTwin platform is:
Metadata-centric –> single source of truth (see our Regulatory Repository)
Automated –> reduce labor cost, increase quality
Processing –> accelerate analysis speed
Synthetic Data –> test and validate early and often (see Synthetic Health Data)
Contact us
Please contact us for more details.