TrialTwin :: Synthetic Health Data
Backstory: Test, Validate Early and Often Without Restrictions
In 2021 we implemented a Proof of Concept project for a large pharma company.
Client was looking for good quality, robust test data to enable the effective development and Quality Control of software solutions and tools that support data collection and transformation.
While test data were often created to support the set-up and testing of data collection tools, the timing and scope of test data creation is prioritized for the processes and milestones these applications and tools are needed for. These data were often created to test procedures developed to detect defects in data or to support selective UAT and often insufficiently represented common data scenarios.
As such, acquiring good quality, fit for purpose test data that is reflective of live data early enough to support the development and testing of downstream data flow processes and tools was highly challenging without potentially impacting the efficiency of the data collection tool development process. In addition, the creation of test data was often a manual labor-intensive process and didn't cover all data scenarios or variations.
Our Solution
We enabled the automated creation of synthesized test data reflective of the study design, creating test data without disrupting the critical path of data collection tool set-up. This solution was able to create test data for entire patients across data domains representing common data scenarios in structures representative of live data extracted from these systems.
We were able to generate 02 types of data: * "Green Data" - compliant with standards and terminologies * "Red Data" - data purposefully created with errors to test the ability of client's software to detect those errors
In 2021 we presented a paper that describes our approach.
You can download a copy of the paper here
Metadata-driven Synthetic Data
Using our Data Standards Governor we're able to generate high-quality, realistic yet not real Synthetic Health Data.
Think of synthetic data as a software-based version of reality: * Artificially-generated people * Including full personal health record * Not based in real patient health data * No usage restrictions * No deanonymization risk * No HIPAA, security, copyright restrictions * Large amounts of data quickly available
In the case of clinical trials:
- Synthetic People assigned to
- Synthetic Trials to build
-
Synthetic Submissions.
- Using Synthetic Health Data clients can
Test Early
Test Often
Test Fully
- and:
Safely
Securely
Privately
Quickly
Inexpensively
Repeatedly
Consistently
- Synthetic Health Data can be used as:
Robust, high-quality test data created to accurately represents expected study data
Test data created in a dynamic, automated way based on the study design (Protocol) and eDC configurations (Medidata Rave ALS)
Test data to represent all anticipated patient journeys through the study
Test data representing all anticipated data that could be collected (representative of all eDC data collection dynamics as defined in the ALS)
- The Synthetic Health Data includes these data domains:
Subject ID form
Demography
Disposition (for each study phase inc. IC, Screening, randomization, end treatment/data collection/study )
Adverse Events
Concomitant Medications
Efficacy data (example)
Visit based data collection (vitals)
Date of visit
Here are some details of the generated data:
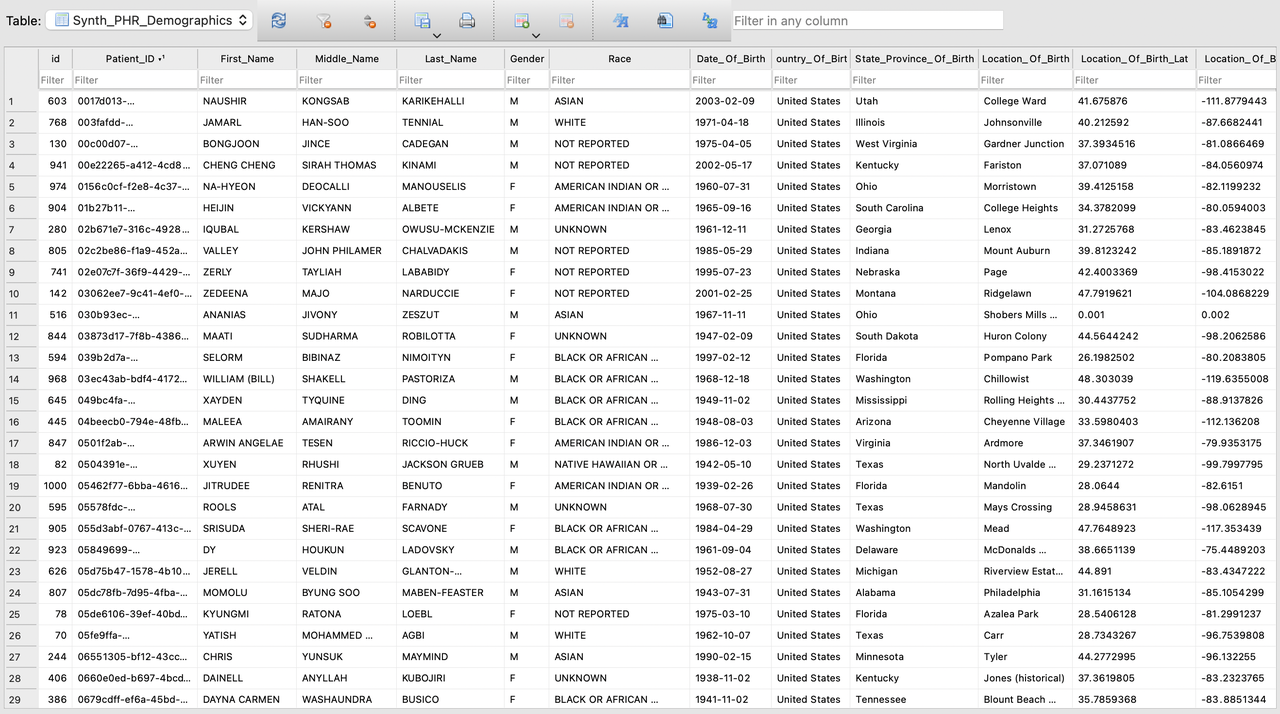
- In this diagram you'll notice that the data shows:
Realistic yet fake full name
User-defined age range, and gender, race %.
Real city / town. With Latitude, Longitude for mapping.
Contact us
Please contact us for more details.